
If you’ve ever wondered how Google finds and indexes your website, or how SEO experts discover technical issues that could be hurting your rankings, you’re in the right place.
Website crawlers are the unsung heroes of the internet – working tirelessly behind the scenes to map out the web and help us understand what’s really happening on our sites.
Whether you’re a complete beginner trying to figure out why your pages aren’t showing up in search results, or you’re looking to level up your SEO game with advanced crawling techniques, this guide has you covered.
We’ll walk through everything from the basics of how crawlers work to hands-on tips for using the best tools available today.
What Is a Website Crawler?
A website crawler (also known as a spider or bot) is a program that automatically browses and indexes web pages for search engines like Google. Think of it as a super-fast robot that visits websites, reads their content, follows links, and takes detailed notes about everything it finds.
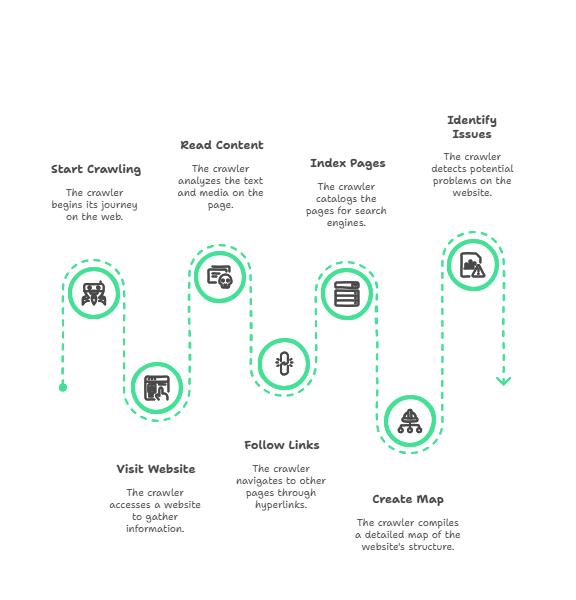
Imagine you’re exploring a massive library where every book is connected to other books through invisible threads. A website crawler is like having a tireless librarian who can follow all those threads simultaneously, cataloging every page, noting what’s on each shelf, and creating a detailed map of how everything connects together.
But crawlers aren’t just for search engines. They’re also incredibly useful tools for website owners, SEO professionals, and developers who want to understand their sites better and fix problems before they impact users or search rankings.
Why Website Crawlers Matter
Here’s the thing – if you’re not using website crawlers to understand your site, you’re essentially flying blind. Recent data from Ahrefs shows that 75% of websites have critical technical SEO issues that can only be discovered through systematic crawling. These tools are game-changers because they:
- Help search engines discover content: Without crawlers, Google wouldn’t know your amazing new blog post exists. They’re the bridge between your content and the search results.
- Find SEO issues like broken links or duplicate content: Ever had a page mysteriously disappear from search results? A crawler might have found the broken link or technical issue that caused it.
- Support technical audits and data extraction: Need to analyze thousands of pages for missing meta descriptions or slow-loading images? Crawlers can do in minutes what would take humans weeks.
The reality is that most website issues are invisible to the naked eye. You might think your site is running perfectly, but a crawler could reveal hundreds of broken internal links, missing alt tags, or duplicate content issues that are quietly hurting your search rankings.
“The difference between successful and struggling websites often comes down to what you can’t see. Crawlers reveal the hidden technical debt that’s silently killing your SEO performance.” – Brian Dean, Backlinko
How Website Crawlers Work
Understanding how crawlers work helps you optimize your site for them. Here’s the fascinating process that happens every time a crawler visits your website:
- Start with a seed URL: Every crawl begins somewhere. This could be your homepage, a specific page you want to analyze, or a list of URLs from your sitemap.
- Follow internal and external links: Like clicking every link on a page, the crawler systematically follows each URL it discovers, building a map of your site’s structure.
- Download and analyze page content: The crawler doesn’t just visit pages – it reads everything. HTML code, images, videos, scripts, and all the metadata that tells search engines what your content is about.
- Store data in an index: All this information gets organized into a searchable database. For Google, this becomes part of their massive search index. For SEO tools, it becomes the data for your audit reports.
What’s really cool is how smart modern crawlers have become. They can respect robots.txt files (instructions telling crawlers which pages to avoid), handle JavaScript-heavy sites, and even simulate how real users experience your website on different devices.
Types of Crawlers
Not all crawlers are created equal. Each type serves different purposes and offers unique insights:
- Search engine crawlers (e.g., Googlebot): These are the big players that determine whether your content appears in search results. Understanding how they work is crucial for SEO success.
- SEO audit crawlers (e.g., Screaming Frog, Sitebulb): These are your diagnostic tools. They crawl your site specifically to find SEO issues and opportunities for improvement.
- Data scraping crawlers (e.g., Crawly, Firecrawl): Perfect for extracting specific information from websites, whether it’s product data, contact information, or content for analysis.
Each type has its strengths. Search engine crawlers focus on indexability and user experience signals. SEO crawlers dig deep into technical optimization opportunities. Data scrapers excel at extracting structured information for business intelligence or competitive analysis.
Top Website Crawling Tools (Compared)
Choosing the right crawler can make or break your SEO efforts. According to SEMrush’s 2024 SEO Tools Survey, 89% of SEO professionals use multiple crawling tools to get comprehensive insights. Here’s an honest comparison of the most popular tools, including what they’re really best at and their limitations:
| Tool | Best For | Free Plan | Key Features |
|---|---|---|---|
| Screaming Frog | SEO Audits | Yes (500 URLs) | Broken links, redirects, metadata, duplicate content |
| Sitebulb | Visual SEO Reports | No | SEO scores, crawl maps, performance insights |
| Crawly | Data Scraping | Yes | Custom spiders, export data |
| Firecrawl | AI-Powered Crawling | Limited | Structured data extraction and search indexing |
Screaming Frog is the Swiss Army knife of SEO crawlers. Its free version handles up to 500 URLs, making it perfect for small sites or specific page audits. The paid version unleashes serious power – unlimited crawls, JavaScript rendering, and custom extraction. If you’re just starting with technical SEO, this should be your first stop.
Sitebulb takes a more visual approach, creating beautiful crawl maps and intuitive reports that make complex technical issues easier to understand. While it doesn’t have a free plan, the insights it provides often justify the cost, especially for agencies presenting findings to clients.
Crawly shines when you need to extract specific data rather than perform SEO audits. It’s particularly useful for competitive research, content analysis, or building databases from web content.
Firecrawl represents the next generation of crawlers, using AI to better understand and extract meaningful information from modern websites. It’s especially powerful for sites with complex JavaScript or dynamic content.
“The tool doesn’t make the SEO expert – understanding what the data means and taking action on it does. Start with free tools and upgrade as your expertise grows.” – Neil Patel, NeilPatel.com
Crawling Modern JavaScript Websites
Here’s where things get tricky. Many modern websites load their content using JavaScript, which means traditional crawlers might miss crucial information. Google’s own research indicates that 40% of websites use JavaScript for critical content rendering, making this a significant challenge for SEO professionals.
Traditional crawlers work like early web browsers – they read the initial HTML and move on. But modern sites often load content dynamically after the page loads. Imagine visiting a restaurant where the menu appears only after you sit down and wait a few seconds. A traditional crawler would see an empty table and leave.
The solution? Use tools that support headless browsing. These crawlers actually execute JavaScript and wait for content to load, just like a real browser would. In Screaming Frog, this is called “JavaScript rendering mode.” Other tools use headless Chrome or Puppeteer to achieve similar results.
Pro tip: Always test both JavaScript-enabled and disabled crawls. The differences in what content appears can reveal critical indexing issues that might be preventing your pages from ranking properly.
Crawl Budget Optimization
What It Is
Your site has a “crawl budget” — how much Googlebot is willing to explore during each visit. Think of it as Google’s time and resources allocated to understanding your website. Moz research shows that optimizing crawl budget can increase indexed pages by up to 200% for large websites.
Google determines your crawl budget based on factors like your site’s authority, how often your content changes, server response speed, and overall site quality. A news website might get crawled multiple times per day, while a small business site might only get a comprehensive crawl once a week.
Tips to Make the Most of It
Optimizing crawl budget is like organizing your home for a very important but time-limited visitor. You want to make sure they see the most important rooms first:
- Block low-value pages using robots.txt: Don’t waste crawl budget on admin pages, search result pages, or duplicate content. Guide crawlers toward your most important content instead.
- Eliminate duplicate content: If Google finds the same content on multiple URLs, it’s wasting time that could be spent discovering your unique, valuable pages.
- Use canonical tags properly: When you have similar or identical content on different URLs, canonical tags tell Google which version is the “main” one worth indexing.
- Fix crawling errors in Google Search Console: Every 404 error or server timeout is time that could have been spent crawling good pages. Regular monitoring prevents these issues from accumulating.
One often-overlooked strategy is optimizing your internal linking structure. Pages that are many clicks away from your homepage get crawled less frequently. By creating logical navigation paths and strategic internal links, you can guide crawl budget toward your most important content.
Canonicalization and Duplicate Content
Duplicate content is like having multiple copies of the same book in a library – it confuses both librarians and visitors about which version is the “real” one. Use canonical tags when multiple URLs have the same or similar content. It helps Google know the “main” version of a page.
Canonical tags are incredibly powerful but often misunderstood. They’re not just for identical content – they’re also useful for very similar pages. For example, if you have a product page that can be accessed through different category paths, the canonical tag points to your preferred URL structure.
Common canonicalization scenarios include:
- HTTP vs HTTPS versions of the same page
- WWW vs non-WWW versions
- Product pages accessible through multiple category paths
- Mobile and desktop versions of content
- Print-friendly versions of articles
A website crawler can quickly identify these issues across your entire site. Look for pages with identical or very similar title tags, meta descriptions, or content. These are prime candidates for canonical optimization.
Website Crawlers vs. Google Search Console
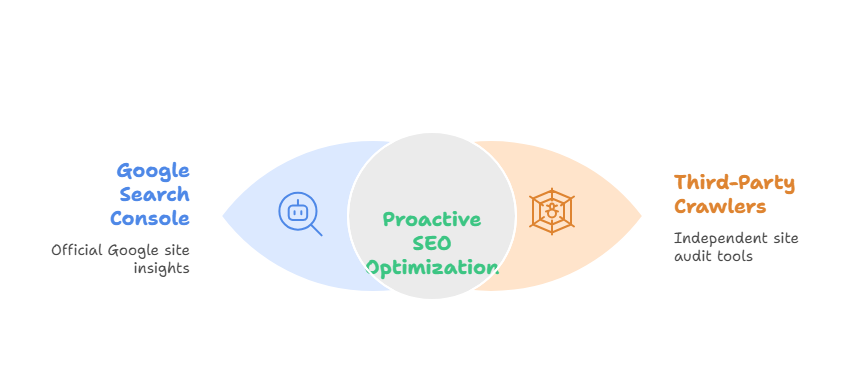
Google Search Console and third-party crawlers complement each other beautifully, but they serve different purposes. Think of GSC as Google’s official report card for your site, while crawlers are your personal tutors helping you study for the test.
GSC Features
- See what pages Google crawls: The Coverage report shows exactly which pages Google has found, indexed, or had trouble with. This is invaluable real-world data.
- Spot indexing or crawl errors: When Google can’t access or understand your pages, GSC tells you about it with specific error messages and affected URLs.
- Submit sitemaps: Direct communication with Google about your site structure and important pages. It’s like giving Google a roadmap to your content.
When to Use Third-Party Crawlers
While GSC shows you Google’s perspective, third-party crawlers give you the full picture:
- To get deeper audits and reports: GSC might tell you about missing meta descriptions, but a crawler shows you exactly which pages are affected and provides bulk export options for fixing them.
- To crawl staging or non-indexed pages: Test your development sites or analyze competitor websites that Google Search Console obviously can’t access.
- To scrape or extract structured data: When you need to analyze content patterns, extract specific elements, or perform competitive research, crawlers excel where GSC can’t help.
The best SEO strategies combine both approaches. Use GSC to understand Google’s current view of your site, then use crawlers to proactively identify and fix issues before they impact your rankings.
“Google Search Console tells you what happened. Third-party crawlers help you prevent what could go wrong. Smart SEOs use both.” – Rand Fishkin, SparkToro
Mobile-First Crawling: What to Know
Google now crawls most sites using a mobile user agent, which means they’re experiencing your website the way smartphone users do. This shift represents one of the biggest changes in how search engines evaluate websites. Search Engine Land reports that 100% of websites are now subject to mobile-first indexing as of 2021.
Mobile-first indexing doesn’t just mean your site needs to look good on phones – it means Google primarily uses the mobile version of your content for indexing and ranking. If your mobile site is missing content, images, or structured data that exists on desktop, those elements essentially don’t exist in Google’s eyes.
Use website crawlers that let you test mobile versions too. Many tools now offer mobile user-agent simulation, allowing you to see exactly what Google’s mobile crawler experiences. Pay special attention to:
- Content parity between desktop and mobile versions
- Image accessibility and alt text on mobile
- Structured data implementation across devices
- Page loading speed on mobile connections
- Internal linking structure on mobile layouts
One common issue crawlers reveal is content that’s hidden or hard to access on mobile devices. Accordion menus, tabbed content, or text that requires user interaction might not be properly crawled or valued by Google’s mobile-first approach.
Latest SEO Crawling Updates (2024)
The SEO landscape evolves rapidly, and 2024 has brought significant changes to how crawlers work and what they prioritize:
- Google uses AI to assess page quality during crawling: Google’s AI integration now evaluates content quality signals during the crawling process, making content relevance more important than ever.
- Core Web Vitals are now assessed in crawl data: Page speed, interactivity, and visual stability are measured during the crawling process, making performance optimization more critical than ever.
- Mobile-first indexing is fully rolled out: Every website is now evaluated primarily through its mobile experience, making mobile optimization non-negotiable.
These updates mean that modern crawlers need to do more than just map your site structure – they need to evaluate user experience signals, performance metrics, and content quality indicators that align with Google’s evolving algorithm.
For SEO professionals, this means your crawling strategy should include regular monitoring of Core Web Vitals, content quality assessments, and mobile usability testing. The days of focusing solely on technical SEO factors are over – modern crawling needs to encompass the full user experience.
How to Use a Website Crawler: Beginner’s Guide
Ready to dive in? Here’s a step-by-step walkthrough that will have you crawling like a pro, even if you’re starting from zero.

Step 1: Choose a Tool
For beginners, start with Screaming Frog’s free version. It’s powerful enough to handle most small to medium websites and provides excellent learning opportunities. Download it, install it, and don’t be intimidated by all the options – we’ll keep things simple at first.
If your site has more than 500 pages, consider investing in the paid version or trying Sitebulb’s free trial. Both offer unlimited crawling and more advanced features that become valuable as you grow more comfortable with the process.
Step 2: Enter Your Website URL
Start with your homepage URL. Make sure you’re using the correct protocol (HTTP vs HTTPS) and the version you want Google to index (with or without www). This initial choice affects how the crawler sees your entire site.
Before hitting “Start,” take a moment to configure basic settings:
- Set a crawl delay if your server is slow or shared hosting
- Enable JavaScript rendering if your site uses it heavily
- Choose whether to follow external links (usually leave this off for initial audits)
Step 3: Review Reports
Once the crawl completes, you’ll see various tabs with different types of data. Focus on these key areas first:
- Broken links: These hurt user experience and waste crawl budget. Priority fix for any website.
- Redirect chains: Multiple redirects slow down crawlers and users. Clean these up for better performance.
- Missing metadata: Pages without title tags or meta descriptions are missed optimization opportunities.
- Content duplicates: Identical or very similar content across multiple URLs confuses search engines and dilutes ranking potential.
Don’t try to fix everything at once. Start with the issues affecting the most pages or your most important content. A few high-impact fixes often yield better results than dozens of minor optimizations.
Step 4: Fix Issues and Re-Crawl
This is where the magic happens. After implementing fixes, run another crawl to verify your changes worked. It’s incredibly satisfying to watch error counts drop and see your site health improve.
Keep a simple spreadsheet tracking what you fixed and when. This helps you measure the impact of changes and builds a valuable reference for future audits. Some improvements show up immediately in crawl data, while others might take weeks to reflect in search rankings.
Best Practices for Crawling Your Own Site
Crawling your own website effectively requires more than just clicking “Start.” Here are the practices that separate amateur audits from professional-grade analysis:
- Use crawl delay to avoid server overload: Set a 1-2 second delay between requests, especially on shared hosting. Overwhelming your server during a crawl can actually create the problems you’re trying to find.
- Exclude admin and login pages: These pages don’t need SEO optimization and including them clutters your reports with irrelevant data. Use robots.txt or crawler settings to skip them.
- Make sure robots.txt and sitemap.xml are updated: Your crawler should respect the same rules as search engines. An outdated robots.txt might prevent crawling of important pages.
Additional pro tips for better crawling results:
- Crawl during off-peak hours to minimize impact on live users
- Save crawl data for historical comparison – trends often reveal more than snapshots
- Test both desktop and mobile user agents to ensure consistency
- Export data to spreadsheets for deeper analysis and team collaboration
- Set up regular crawl schedules for large sites to catch issues early
Remember that crawling is an ongoing process, not a one-time audit. Websites change constantly – new pages get added, content gets updated, and technical issues emerge. Successful SEO professionals make crawling a regular part of their maintenance routine.
Long-Tail Keywords You Should Target
Smart SEO isn’t just about crawling your current content – it’s about understanding what people are actually searching for. These long-tail keywords represent real questions people have about website crawling:
- “How to crawl a website for SEO”: Perfect for tutorial content and step-by-step guides
- “Best website crawler tool for beginners”: Targets people just starting their SEO journey
- “SEO website audit using a crawler”: Appeals to those ready to take action on their sites
- “Free crawler to find broken links”: Addresses a specific, common problem with a solution-focused approach
These keywords work because they match real user intent. Someone searching “how to crawl a website for SEO” isn’t just browsing – they have a specific problem to solve and are looking for actionable guidance.
When creating content around these terms, focus on providing genuine value rather than just hitting keyword targets. Answer the complete question, provide context, and give people enough information to actually succeed with their crawling efforts.
“Long-tail keywords aren’t just SEO tactics – they’re windows into what your audience actually needs. Answer those needs, and rankings follow naturally.” – Marie Haynes, Marie Haynes Consulting
Final Thoughts
Website crawlers are essential for SEO success, but they’re only as valuable as the actions you take based on their insights. The best crawler in the world won’t improve your rankings if you don’t act on what it discovers.
Start simple, focus on high-impact issues first, and gradually expand your crawling sophistication as you become more comfortable with the tools and concepts. Remember that crawling is about understanding your website from both search engine and user perspectives – technical perfection means nothing if it doesn’t improve the actual user experience.
Use crawlers regularly to detect issues, improve rankings, and keep your site optimized for both users and search engines. The websites that consistently rank well aren’t necessarily the ones with perfect initial setups – they’re the ones that continuously monitor, identify issues, and make improvements based on solid data.
Whether you’re fixing your first broken link or optimizing crawl budget for an enterprise site, the principles remain the same: understand how crawlers see your content, identify obstacles to discovery and indexing, and systematically remove barriers between your valuable content and the people searching for it.
