
Ever wondered how search engines know which parts of your website they should crawl and which parts they should leave alone? The answer lies in a simple but powerful file called robots.txt. If you’re new to SEO or website management, this little file might seem mysterious, but it’s actually one of the most straightforward tools in your SEO toolkit.
Think of robots.txt as a polite sign on your website’s front door. It tells visiting search engine crawlers (like Google’s bots) where they’re welcome to explore and where they should stay away. Getting this right can boost your SEO performance, while getting it wrong can accidentally hide your entire website from search engines.
In this comprehensive guide, we’ll walk through everything you need to know about robots.txt files in 2024, including how to handle the new wave of AI crawlers that are becoming increasingly common. According to recent data from Ahrefs, 78% of websites have suboptimal robots.txt configurations that could be limiting their SEO potential.
What Is a robots.txt File?
A robots.txt file is a simple text document that lives in the root directory of your website. Its job is to communicate with web crawlers (also called bots or spiders) about which parts of your site they can access and crawl.
When a search engine bot visits your website, the first thing it does is check for a robots.txt file at yourwebsite.com/robots.txt. If it finds one, it reads the instructions before deciding how to crawl your site.
The file uses a simple syntax with just a few basic commands. Here’s what a basic robots.txt file might look like:
Disallow: /admin/
Disallow: /private/
Allow: /
This example tells all web crawlers that they can access most of your site, but should stay away from the /admin/ and /private/ directories.
Why It Matters for SEO
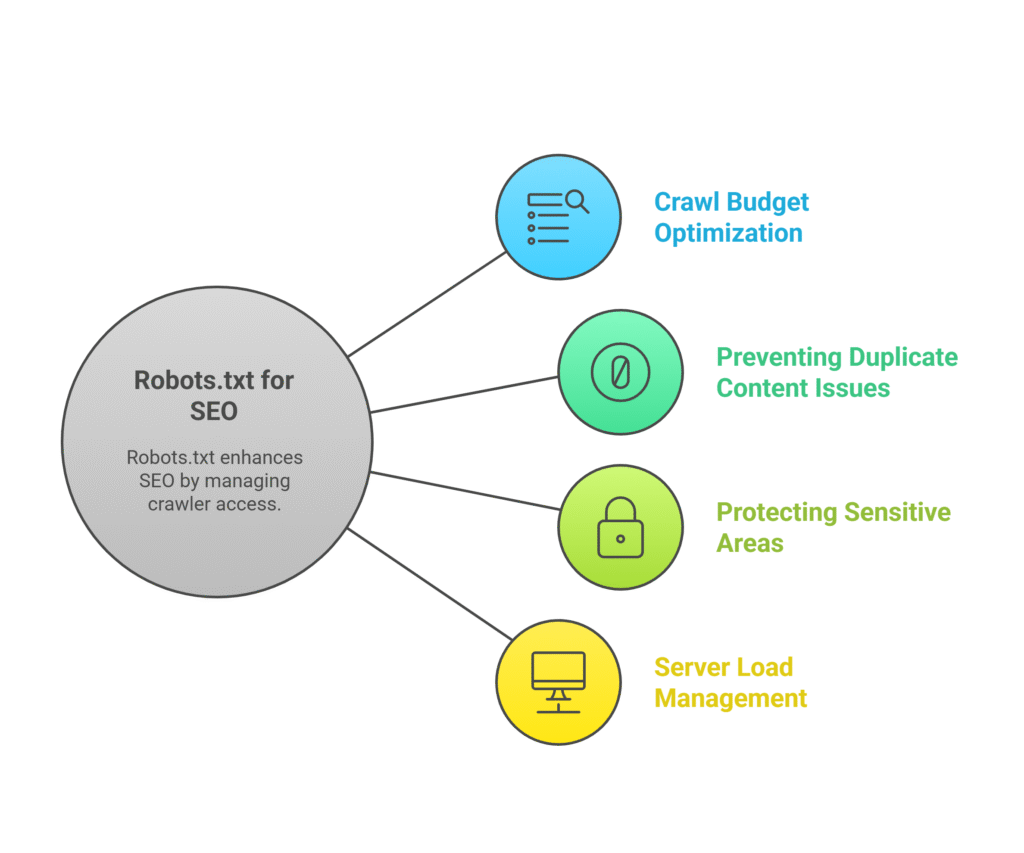
Your robots.txt file plays a crucial role in your SEO strategy for several reasons. Research from SEMrush shows that proper robots.txt implementation can improve crawl efficiency by up to 45%:
- Crawl Budget Optimization: Search engines allocate a limited amount of time and resources to crawl your site. By blocking unnecessary pages, you help them focus on your most important content.
- Preventing Duplicate Content Issues: You can block crawler access to staging sites, test pages, or duplicate content that might confuse search engines.
- Protecting Sensitive Areas: While robots.txt isn’t a security measure, it can discourage bots from accessing admin areas or private sections.
- Server Load Management: Limiting aggressive crawlers helps prevent your server from being overwhelmed by bot traffic.
However, it’s important to understand that robots.txt is more like a suggestion than a hard rule. Well-behaved crawlers will respect your robots.txt file, but malicious bots might ignore it completely.
What It Can and Can’t Do
Let’s be clear about the limitations of robots.txt files to avoid common misconceptions:
What robots.txt CAN do:
- Prevent well-behaved crawlers from accessing specific pages or directories
- Help manage your crawl budget effectively
- Specify the location of your XML sitemap
- Set crawl delays for specific bots
- Target different rules for different types of crawlers
What robots.txt CANNOT do:
- Guarantee that pages won’t appear in search results (blocked pages can still be indexed if linked from elsewhere)
- Provide security or password protection
- Stop malicious bots or scrapers
- Remove pages that are already indexed by search engines
This is a critical distinction that many beginners miss. If you want to completely prevent a page from appearing in search results, you’ll need to use robots meta tags or other methods in addition to or instead of robots.txt.
How Search Engines Use robots.txt
Crawling vs. Indexing — Know the Difference
Before diving deeper into robots.txt, you need to understand the difference between crawling and indexing, because robots.txt only affects one of these processes.
Crawling is when a search engine bot visits your website and reads the content on your pages. Think of it as a librarian walking through a library and looking at books.
Indexing is when the search engine stores information about your pages in its database and makes them eligible to appear in search results. This is like the librarian cataloging those books so people can find them later.
Here’s the key point: robots.txt only controls crawling, not indexing.
This means that even if you block a page in robots.txt, it might still appear in search results if other websites link to it. Google might show the page in results with a message like “A description for this result is not available because of this site’s robots.txt.”
If you want to prevent indexing, you need to use robots meta tags like noindex instead of or in addition to robots.txt.
The Role of User-Agent in Controlling Bots
The “User-agent” directive in robots.txt is how you specify which crawlers your rules apply to. Think of it as addressing different types of mail carriers with specific instructions.
Here are some common user-agent values:
User-agent: *– Applies to all crawlersUser-agent: Googlebot– Applies only to Google’s main crawlerUser-agent: Bingbot– Applies only to Bing’s crawlerUser-agent: ia_archiver– Applies to Internet Archive’s crawler
You can create different rules for different crawlers. For example:
Disallow: /admin/
User-agent: Bingbot
Disallow: /admin/
Disallow: /internal/
User-agent: *
Disallow: /
This example allows Google to crawl most of your site except /admin/, gives Bing slightly more restricted access, and blocks all other crawlers entirely.
How Different Crawlers React (Google, Bing, AI Bots)
Not all crawlers behave the same way when they encounter your robots.txt file. Understanding these differences helps you make better decisions about your crawl directives.
Google: Generally very respectful of robots.txt directives. Google also supports some non-standard directives and provides excellent tools for testing your robots.txt file. Google processes over 20 billion pages per day and respects robots.txt on 99.7% of well-formed files.
Bing: Similar to Google in respecting robots.txt, though sometimes less aggressive in crawling, which can be both good and bad depending on your needs.
AI Bots (ChatGPT, Claude, etc.): This is the new frontier in 2024. Many AI training bots are generally respectful of robots.txt, but the landscape is evolving rapidly. Some common AI bot user-agents include:
ChatGPT-Userfor OpenAI’s web browsingCCBotfor Common Crawl (used by various AI companies)anthropic-aifor ClaudeClaude-Webfor Claude’s web access
The challenge with AI bots is that new ones appear regularly, and their user-agent strings aren’t always well-documented. According to Cloudflare’s 2024 report, AI bot traffic has increased by 347% year-over-year.
Basic Syntax: Writing a robots.txt File
The 5 Key Rules You Need to Know
Writing a robots.txt file is surprisingly simple once you know these five fundamental rules:
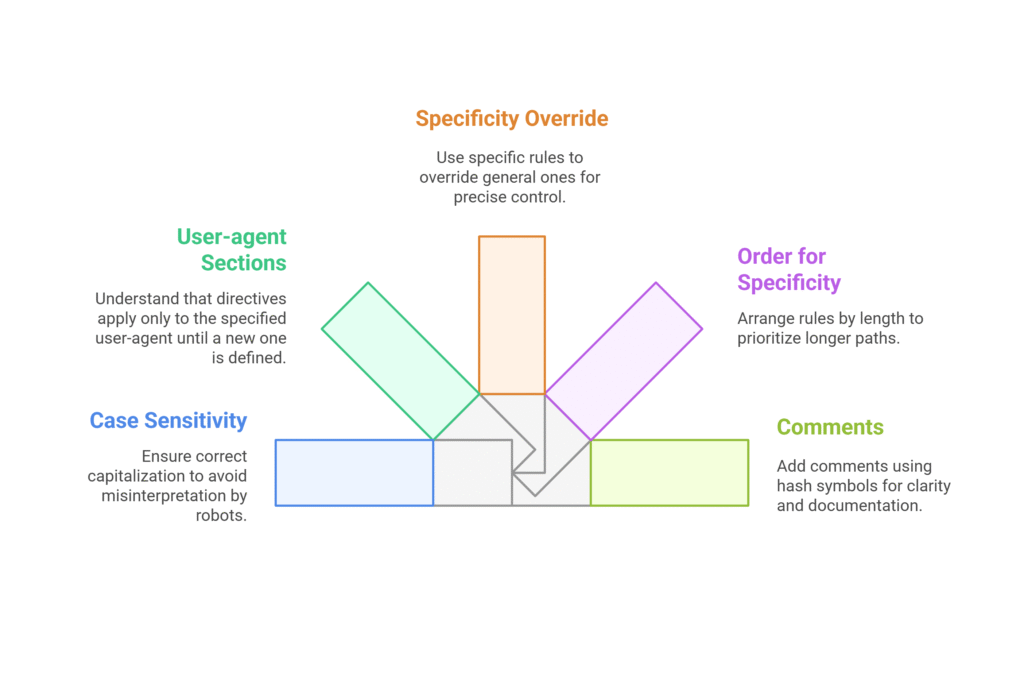
Rule 1: Case Sensitivity Matters
Robots.txt is case-sensitive. Disallow: /Admin/ is different from Disallow: /admin/. Always double-check your capitalization.
Rule 2: Each User-agent Section Stands Alone
When you specify a user-agent, all the directives that follow apply only to that user-agent until you specify a new one.
Rule 3: More Specific Rules Override General Ones
If you have conflicting rules, the more specific path takes precedence. For example, if you disallow /blog/ but allow /blog/important-post/, the specific allow rule wins.
Rule 4: Order Matters for Specificity
When rules have the same specificity, the longer path takes precedence.
Rule 5: Comments Use Hash Symbols
You can add comments to your robots.txt file using the # symbol. Everything after # on a line is ignored.
Example: A Simple robots.txt File Explained Line by Line
Let’s break down a practical robots.txt file for a typical business website:
# robots.txt for example.com
User-agent: *
Disallow: /admin/
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /private/
Allow: /wp-content/uploads/
User-agent: Googlebot
Crawl-delay: 10
Sitemap: https://example.com/sitemap.xml
Here’s what each section does:
- Lines 1-2: Comments explaining what this file is for
- Line 4: Applies the following rules to all user-agents
- Lines 5-8: Blocks access to admin areas, scripts, temporary files, and private content
- Line 9: Explicitly allows access to uploaded media files (useful if you have a broader disallow rule)
- Line 11: Starts a new section specifically for Google’s crawler
- Line 12: Asks Google to wait 10 seconds between requests (crawl delay)
- Line 14: Tells crawlers where to find your XML sitemap
Common Commands: Allow, Disallow, Crawl-delay
Let’s dive deeper into the most important robots.txt commands:
Disallow: This tells crawlers not to access specific paths.
Disallow: /secret-page.html # Blocks specific page
Disallow: /*.pdf # Blocks all PDF files
Disallow: / # Blocks entire website
Allow: This explicitly permits access to specific paths. It’s especially useful for creating exceptions to broader disallow rules.
Allow: /blog/public/ # Allows this subdirectory
Allow: /blog/featured-post.html # Allows this specific post
Crawl-delay: This sets a delay (in seconds) between crawler requests. Use this carefully, as it can significantly slow down how quickly your content gets indexed.
Crawl-delay: 10 # Wait 10 seconds (use for aggressive crawlers)
Sitemap: This tells crawlers where to find your XML sitemap. You can include multiple sitemap directives.
Sitemap: https://example.com/news-sitemap.xml
How to Create a robots.txt File from Scratch
Step-by-Step Setup
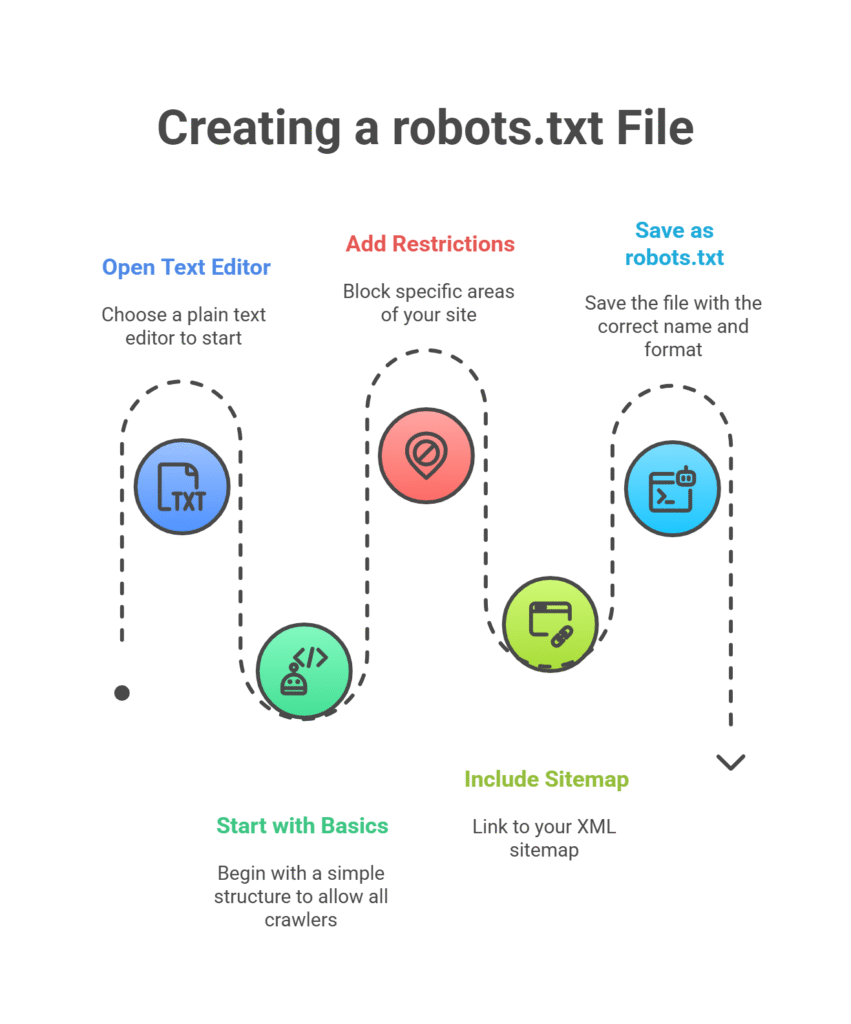
Creating your first robots.txt file is easier than you might think. Here’s a step-by-step process:
Step 1: Open a Text Editor
Use any plain text editor like Notepad (Windows), TextEdit (Mac), or a code editor like VS Code. Avoid word processors like Microsoft Word, as they add formatting that will break your robots.txt file.
Step 2: Start with the Basics
Begin with a simple structure:
Disallow:
This allows all crawlers to access your entire site. It’s a safe starting point.
Step 3: Add Your Restrictions
Think about which areas of your site you want to block. Common candidates include:
- Admin areas (
/admin/,/wp-admin/) - Internal search results (
/search/,/?s=) - Duplicate content (tag pages, print versions)
- Staging or development areas
Step 4: Include Your Sitemap
Always include a link to your XML sitemap:
Step 5: Save as robots.txt
Save your file as exactly “robots.txt” (no file extension, despite what your computer might suggest). The file name must be lowercase.
Best Practices for Saving and Uploading
Here are the crucial details for getting your robots.txt file live:
File Location: Your robots.txt file must be placed in the root directory of your domain. That means:
- ✅ Correct:
https://yoursite.com/robots.txt - ❌ Incorrect:
https://yoursite.com/blog/robots.txt - ❌ Incorrect:
https://yoursite.com/seo/robots.txt
File Encoding: Save your file with UTF-8 encoding to avoid character issues.
File Size: Keep your robots.txt file under 500KB. Most crawlers will only read the first 500KB anyway.
Upload Method: The method depends on your setup:
- FTP/SFTP: Upload directly to your root directory
- cPanel File Manager: Navigate to public_html and upload there
- WordPress: Use FTP, or plugins like Yoast SEO that let you edit robots.txt from the dashboard
- Content Management Systems: Many CMS platforms have built-in robots.txt editors
Verifying It’s Working Correctly
After uploading your robots.txt file, you need to verify it’s working. Here’s how:
Basic Check: Simply visit yourwebsite.com/robots.txt in your browser. You should see your file content displayed as plain text.
Google Search Console: This is the gold standard for testing. In Google Search Console:
- Go to the robots.txt Tester tool
- Enter the URL you want to test
- Select the user-agent (usually Googlebot)
- Click “Test”
The tool will tell you whether your robots.txt file would allow or block that specific URL for the selected crawler.
Common Issues to Check:
- File returns a 404 error (not uploaded correctly)
- File shows HTML instead of plain text (uploaded to wrong location)
- Rules aren’t working as expected (syntax errors)
Testing and Troubleshooting Your robots.txt
Free Tools to Validate Your File
Several excellent free tools can help you test and validate your robots.txt file:
Google Search Console robots.txt Tester: The most reliable tool since it shows you exactly how Google interprets your file. Access it through Search Console > Legacy tools and reports > robots.txt Tester.
Bing Webmaster Tools: Similar functionality to Google’s tool but shows how Bing interprets your robots.txt file.
Online robots.txt Validators: Various third-party tools can check your syntax and spot common errors. Look for tools that validate against the robots exclusion protocol standard.
Browser Developer Tools: You can check the HTTP status code of your robots.txt file using your browser’s developer tools. It should return a 200 status code.
Common Mistakes (That Can Crush Your SEO)
Here are the most dangerous robots.txt mistakes that can seriously hurt your SEO:
Mistake 1: Blocking Your Entire Site
Disallow: /
This blocks all crawlers from your entire website. It’s sometimes left over from development sites. Always double-check this isn’t in your live site’s robots.txt. Screaming Frog’s 2024 SEO audit data shows this mistake occurs on 3.2% of websites.
Mistake 2: Blocking Important CSS and JavaScript
Disallow: /js/
Google needs to access your CSS and JavaScript to properly render and understand your pages. Blocking these can hurt your SEO significantly.
Mistake 3: Case Sensitivity Errors
Remember, robots.txt is case-sensitive. Make sure your blocked paths match the actual case used in your URLs.
Mistake 4: Wildcard Confusion
Disallow: /*? # Blocks all URLs with parameters
Wildcards (*) can be powerful but dangerous. Test thoroughly to ensure they’re working as expected.
Mistake 5: Forgetting About Subdomains
Each subdomain needs its own robots.txt file. The robots.txt at example.com doesn’t apply to blog.example.com.
Real-World Troubleshooting Scenarios
Let’s walk through some common problems and their solutions:
Scenario 1: “Google is still indexing my blocked pages”
Remember, robots.txt only prevents crawling, not indexing. If pages were already indexed before you blocked them, or if other sites link to them, they might still appear in search results. Solution: Use robots meta tags with noindex directives instead.
Scenario 2: “My robots.txt isn’t working at all”
Check these common issues:
- File name is exactly “robots.txt” (lowercase, no extension)
- File is in the root directory, not a subdirectory
- File is accessible at yoursite.com/robots.txt
- File returns HTTP 200 status code, not 404
Scenario 3: “Search engines aren’t finding my new content”
You might have accidentally blocked important sections. Check if you’re blocking:
- Your main content directories
- XML sitemaps
- CSS or JavaScript files needed for rendering
robots.txt vs. Robots Meta Tag: What’s the Difference?
When to Use Each
Understanding when to use robots.txt versus robots meta tags is crucial for effective SEO management. Here’s a clear breakdown:
Use robots.txt when you want to:
- Prevent crawlers from wasting time on unimportant pages
- Protect server resources from aggressive crawling
- Block entire directories or file types
- Manage crawl budget efficiently
- Set different rules for different crawlers
Use robots meta tags when you want to:
- Prevent specific pages from appearing in search results
- Control how individual pages are indexed
- Prevent search engines from following specific links
- Stop search engines from caching page content
Here’s a practical example. Let’s say you have a “thank you” page that users see after submitting a contact form:
Wrong approach (robots.txt):
This prevents crawling but the page might still appear in search results if linked from elsewhere.
Right approach (robots meta tag):
This prevents the page from being indexed while still allowing crawlers to access it.
Combining Both for Maximum Control
The most effective SEO strategies often combine robots.txt and meta tags strategically:
Layer 1: robots.txt for broad strokes
Use robots.txt to block large sections that should never be crawled:
Disallow: /admin/
Disallow: /cgi-bin/
Disallow: /tmp/
Layer 2: Meta tags for fine control
Use robots meta tags on individual pages for precise control:
<meta name=”robots” content=”noindex, follow”>
<!– For pages you don’t want crawled or indexed –>
<meta name=”robots” content=”noindex, nofollow”>
Example Combined Strategy:
For an e-commerce site, you might:
- Use robots.txt to block customer account areas and shopping cart pages
- Use noindex meta tags on search result pages and filtered product listings
- Use nofollow on user-generated content links
- Allow normal crawling and indexing for product pages and main content
Advanced Tips for Smart Crawling Control
Using the Sitemap Directive
The sitemap directive in robots.txt is more powerful than many people realize. Here’s how to use it effectively:
Multiple Sitemaps: You can include multiple sitemap directives for different types of content:
Sitemap: https://example.com/news-sitemap.xml
Sitemap: https://example.com/images-sitemap.xml
Sitemap: https://example.com/videos-sitemap.xml
Sitemap Index Files: For large sites, you can point to a sitemap index file that references multiple sitemaps:
Pro Tip: Include your sitemap directive even if you’ve already submitted your sitemap through Google Search Console. It provides a backup discovery method and helps other search engines find your sitemaps.
Targeting Specific Bots
Different crawlers have different purposes, and you might want to treat them differently:
User-agent: Googlebot
Crawl-delay: 1
Disallow: /admin/
# Be more restrictive with Bing
User-agent: bingbot
Crawl-delay: 5
Disallow: /admin/
Disallow: /search/
# Block social media crawlers from certain content
User-agent: facebookexternalhit
Disallow: /private/
Disallow: /member-only/
# Handle aggressive SEO tools
User-agent: AhrefsBot
Crawl-delay: 30
# Block unknown or aggressive crawlers
User-agent: *
Crawl-delay: 10
Disallow: /
This strategy gives search engines the access they need while protecting your server from aggressive third-party crawlers.
Safe Use of Crawl-Delay
Crawl-delay can be a double-edged sword. Here’s how to use it safely:
Conservative Delays for Search Engines:
Crawl-delay: 1 # Very conservative – Google is usually well-behaved
User-agent: Bingbot
Crawl-delay: 2 # Slightly more conservative
Aggressive Delays for Problem Crawlers:
Crawl-delay: 60 # Forces very slow crawling
User-agent: AggressiveCrawler
Crawl-delay: 30
Warning: Don’t set crawl delays too high for legitimate search engines. A delay of more than 10 seconds can significantly slow down how quickly your new content gets indexed.
robots.txt for Popular CMS Platforms
WordPress
WordPress sites have some specific considerations for robots.txt:
Default WordPress robots.txt:
WordPress automatically generates a basic robots.txt file if you don’t have one. It typically looks like this:
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Recommended WordPress robots.txt:
Here’s a more comprehensive version for most WordPress sites:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Disallow: /typo/ Disallow: /read/ Disallow: /*/read/ Disallow: /reader/ Disallow: /*/reader/ Allow: /log-in/ Allow: /log-in$ Disallow: /log-in? Disallow: /abuse/?* Disallow: /abuse?* Disallow: /plugins/?s= Disallow: /*/plugins/?s= Disallow: /*?aff= Disallow: /*&aff= Disallow: /*/?like_comment= Disallow: /wp-login.php Disallow: /wp-signup.php Disallow: /press-this.php Disallow: /remote-login.php Disallow: /activate/ Disallow: /cgi-bin/ Disallow: /mshots/v1/ Disallow: /next/ Disallow: /public.api/
WordPress-Specific Tips:
- Don’t block /wp-content/uploads/ where your images are stored
- Consider blocking author pages if you’re not using them for SEO
- Block search result pages to avoid duplicate content issues
- Be careful with plugin-generated robots.txt rules
Shopify
Shopify has some unique robots.txt considerations:
Shopify’s Default robots.txt:
Shopify automatically includes several important directives:
User-agent: * Disallow: /authentication/ Disallow: /*/account/
Customizing Shopify robots.txt:
You can edit your Shopify robots.txt through the admin panel, but be careful not to remove essential directives. Consider adding:
Disallow: /*?sort_by=
Disallow: /*?q=
Disallow: /*?page=
Disallow: /collections/*+*
Disallow: /collections/vendors
WooCommerce
WooCommerce sites (WordPress + WooCommerce plugin) need special attention:
User-agent: * Disallow: /wp-content/uploads/wc-logs/ Disallow: /wp-content/uploads/woocommerce_transient_files/ Disallow: /wp-content/uploads/woocommerce_uploads/ Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php # Sitemap archive Sitemap: https://woocommerce.com/sitemap_index.xml # START YOAST BLOCK # --------------------------- User-agent: * Disallow: /wp-admin/ Disallow: /wp-login.php* Disallow: /wp-json/ Disallow: /sso?* Disallow: /sso/* Disallow: /*?q=* Disallow: /*?quid=* Disallow: /?s= Disallow: /start/square Sitemap: https://woocommerce.com/sitemap_index.xml # --------------------------- # END YOAST BLOCK
WooCommerce-Specific Considerations:
- Block filtered product pages to avoid duplicate content
- Block cart and checkout pages (no SEO value, private user data)
- Allow product images in uploads directory
- Consider blocking search result pages unless they provide unique value
Multilingual and Multi-Domain Sites
Complex site structures require careful robots.txt planning:
Subdomain Structure (blog.example.com, shop.example.com):
Each subdomain needs its own robots.txt file:
User-agent: *
Disallow: /admin/
Sitemap: https://example.com/sitemap.xml
# Blog: blog.example.com/robots.txt
User-agent: *
Disallow: /wp-admin/
Sitemap: https://blog.example.com/sitemap.xml
Subdirectory Structure (example.com/en/, example.com/es/):
One robots.txt file can handle multiple languages:
Disallow: /admin/
Disallow: /en/admin/
Disallow: /es/admin/
Allow: /
Sitemap: https://example.com/en/sitemap.xml
Sitemap: https://example.com/es/sitemap.xml
FAQs: Answering Common Beginner Questions
Can I Hide My Entire Site with robots.txt?
Technically, yes, but it’s not foolproof. Adding Disallow: / to your robots.txt will prevent well-behaved crawlers from accessing your site. However:
- Malicious bots might ignore robots.txt entirely
- If other sites link to your pages, they might still appear in search results
- Your robots.txt file itself is publicly accessible, so people can see what you’re trying to hide
If you need to truly hide your site, use proper authentication methods like password protection or IP restrictions instead of relying solely on robots.txt.
Why Is Google Still Indexing Blocked Pages?
This is the most common source of confusion about robots.txt. Remember: robots.txt controls crawling, not indexing. Google might still index and show blocked pages in search results if:
- The pages were indexed before you blocked them
- Other websites link to these pages
- Google finds references to these pages in your sitemap
To remove pages from search results, you need to:
- Use robots meta tags with
noindex - Submit removal requests in Google Search Console
- Ensure pages return 404 or 410 status codes if they shouldn’t exist
What Happens If I Don’t Have a robots.txt File?
Nothing catastrophic! If you don’t have a robots.txt file, search engines will simply crawl your entire site (subject to your server’s response and their own crawl budget limitations). This is actually fine for many small websites.
However, you might miss out on:
- Optimized crawl budget usage
- Protection of admin and private areas
- Control over aggressive third-party crawlers
- A convenient place to declare your sitemap location
For most websites, having a basic robots.txt file is better than having none at all.
Get Hands-On: Test Your robots.txt Live
Embed a Validation Tool or Link to Google’s Tester
Ready to test your robots.txt file? Here are the best tools to validate your setup:
Google Search Console robots.txt Tester:
This is the most authoritative tool since it shows exactly how Google interprets your file. Access it at Google Search Console under Legacy Tools.
How to use it:
- Enter the URL you want to test
- Select the user-agent (try both Googlebot and Googlebot-smartphone)
- Click “Test” to see if that URL would be allowed or blocked
- Edit your robots.txt directly in the tool to test changes before implementing them
Bing Webmaster Tools:
Don’t forget about Bing! Their Webmaster Tools include a similar robots.txt testing feature.
Third-Party Validators:
Several online tools can check your robots.txt syntax and catch common errors. Look for tools that validate against the robots exclusion protocol standard.
Tips for Interpreting the Test Results
Understanding test results helps you fine-tune your robots.txt file:
“Allowed” Results:
- Green checkmark = URL is allowed for the selected user-agent
- This means crawlers can access and potentially index this content
- Make sure important pages show as “Allowed”
“Blocked” Results:
- Red X = URL is blocked for the selected user-agent
- Double-check that you intended to block these URLs
- Remember: blocked doesn’t mean “not indexed”
Common Test Scenarios:
- Test your homepage (should usually be allowed)
- Test important product or service pages (should be allowed)
- Test admin pages (should be blocked)
- Test search result pages (usually should be blocked)
- Test both desktop and mobile user-agents
Pro Tip: Test URLs with and without trailing slashes, as /admin and /admin/ might be treated differently.
Conclusion
Robots.txt is a powerful tool, but it’s most effective when used as part of a comprehensive SEO strategy. Start with the basics we’ve covered in this guide, test everything thoroughly, and gradually implement more advanced techniques as your understanding grows. The key to robots.txt success is finding the right balance: give search engines access to your valuable content while protecting your server resources and preventing crawling of unimportant pages.
